지금부터는 앞 내용이 뒷 내용에 영향을 미치는 직렬 관계라기 보다는 병렬 관계에 가깝습니다. 그러니 앞 내용을 완전히 이해하지는 못해도 뒷 내용을 보는데 지장은 없을 겁니다. 자 그럼 이제 랜덤 워크(Random walk) 프로세스를 볼까요?
16.1 의 식을 설명하자면,
'모든 독립이고 동일 분포를 가지는(약자로는 IID) U_i에 대해서, 결과값 k=-1 과 k=1이 각각 p=0.5의 확률로 나타날 때, X_n은 지금까지 시도된 모든 U_i들의 합으로 정의한다.'
입니다. 이것이 랜덤 워크라고 불리는 것은 0.5의 확률로 오른쪽으로 갈지 왼쪽으로 갈지를 결정하기 때문입니다. 수직선 위에 사람이 서있다고 하고 U_i는 (i+1)번째 걸음이라고 하면 X_n은 그 사람의 변위라고 할 수 있습니다.
그럼 바로 아래의 식을 봅시다. 이 식은 위의 랜덤 워크를 프로세스로 바꾼 것입니다. 앞서 배운 notation을 기억하신다면, X[N, S] 형태를 떠올리실 수 있을 것입니다. 그것은 결과를 보고 이야기할 때 쓰는 notation인데요, 왜냐하면 앙상블이 여러 개 있어야 하기 때문이고 앙상블을 기록할 수 있는 조건은 프로세스가 수행되야 한다는 것이죠. 프로세스를 수행하지 않으면 결과가 없고, 기록할 앙상블도 없는 것입니다. 이 식은 결과를 이야기 하기 전의 식이므로 앙상블에 대한 변수가 정의되지 않으므로 X[N] 형태의 notation이 됩니다. 여기서 N은 sample space element인 것이죠.
이를 일반적인 notation으로 생각해본다면, X[(time)] 이라고 생각할 수 있습니다. n이나 t 등은 '시간'이라고 말씀드렸기 때문이죠. 마찬가지로 보면, U[i]역시 i라는 시간에 대해서 위에 있던 '걸음'을 재정의한 것입니다. 즉, U[i]는 'i번째 걸음'이라는 뜻이죠.
이러한 랜덤 워크 프로세스는 실생활에서 그 예시를 많이 찾아볼 수 있습니다. 저와 여러분이 가위바위보를 해서 여러분이 이기면 제가 모찌떡 하나를 드리고 제가 이기면 여러분이 저한테 모찌떡 하나를 주시면 되는 그런 심플한 게임은 사실 랜덤 워크 프로세스인 것이죠. (모찌떡이 먹고 싶었습니다.)
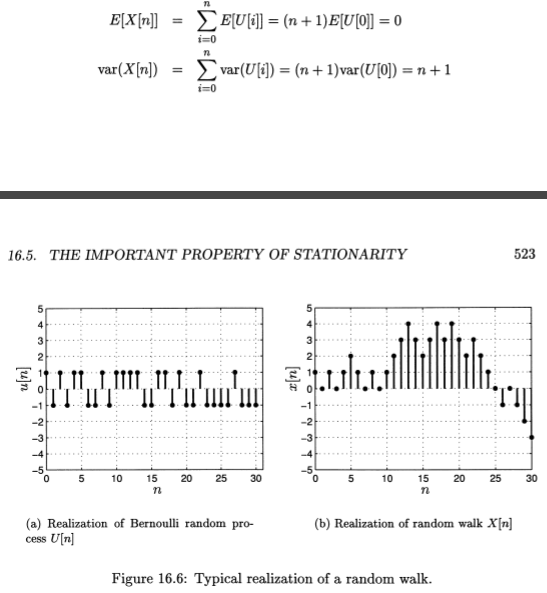
눈치채신 분도 계시겠지만, 사실 U_i는 베르누이 확률변수의 결과값인 0과 1대신에 -1과 1로 바꿔치기 한 것 뿐입니다. 하지만 바뀐게 있습니다. 베르누이 랜덤 프로세스는 매 X[n] (n번째 베르누이 확률변수) 의 평균이 0.5 였다면, U[i] (i번째 U_i)의 평균은 0입니다. 따라서 전체 (n+1)걸음을 걸었을 때의 평균 변위는 0이 되는 것이죠. 만약 랜덤 워크가 아니라 베르누이 랜덤 프로세스였다면 평균은 (n+1)/2 가 되었을 것입니다.
눈치가 더 좋으시다면 이 식에서 IID가 랜덤 프로세스에 미치는 영향도 알 수 있으실 겁니다. U[0] represent U[i]/(n+1)이라는 것이죠. 이것 때문에 평균이 (n+1)U[0]가 되며 분산이 (n+1)Var(U[0])가 되는 것입니다. 이것이 전부 IID에서 나오는 성질입니다.
이 프로세스를 수행하면 위와 같은 앙상블을 얻을 수 있습니다. 앙상블이 하나밖에 없으므로 여기서도 S가 생략됐습니다.
이번 글에서는 베르누이와 변형된 베르누이(랜덤 워크) 프로세스를 보았으며, IID 프로세스의 성질에 대해서 살펴보았습니다. 다음 글에서는 IID에 의해 일어나는 성질인 'Stationary'에 대해 알아보겠습니다.
'배워가는 날들 > 확률변수' 카테고리의 다른 글
| 확률변수의 기본 (8) 가우시안 백색 잡음 (White Gaussian Noise) 과 Multivariate random process (0) | 2018.07.13 |
|---|---|
| 확률변수의 기본 (7) Stationary random process (0) | 2018.07.13 |
| 확률변수의 기본 (5) 랜덤 프로세스의 정의와 자료형에 따른 랜덤 프로세스의 분류 (0) | 2018.07.13 |
| 확률변수의 기본 (4) 합성곱 (1) | 2018.07.13 |
| 확률변수의 기본 (3) 분산과 공분산의 정의와 그 의미 (0) | 2018.07.13 |

Amorest